Usuwanie duplikatów w Excelu wygląda prosto tylko na pierwszy rzut oka. W praktyce pytanie, jak usunąć powtarzające się wiersze w Excelu, sprowadza się do wyboru właściwej metody: jednorazowego czyszczenia, bezpiecznego filtrowania albo automatyzacji dla danych, które wracają cyklicznie. Poniżej pokazuję, jak zrobić to szybko, kiedy zachować ostrożność i jak nie zepsuć sobie analizy.
Najważniejsze wnioski przed czyszczeniem danych
- Usuń duplikaty usuwa rekordy trwale, więc przed startem warto zrobić kopię arkusza.
- Excel zachowuje pierwsze wystąpienie wartości, a pozostałe kopie usuwa.
- Jeśli wybierzesz tylko część kolumn, Excel nadal usuwa całe wiersze na podstawie tych kolumn.
- Gdy chcesz tylko zobaczyć unikalne wartości, lepiej użyć filtra zaawansowanego albo funkcji
UNIQUE. - Przy raportach cyklicznych najlepiej sprawdza się Power Query, bo porządkuje dane przy każdym odświeżeniu.
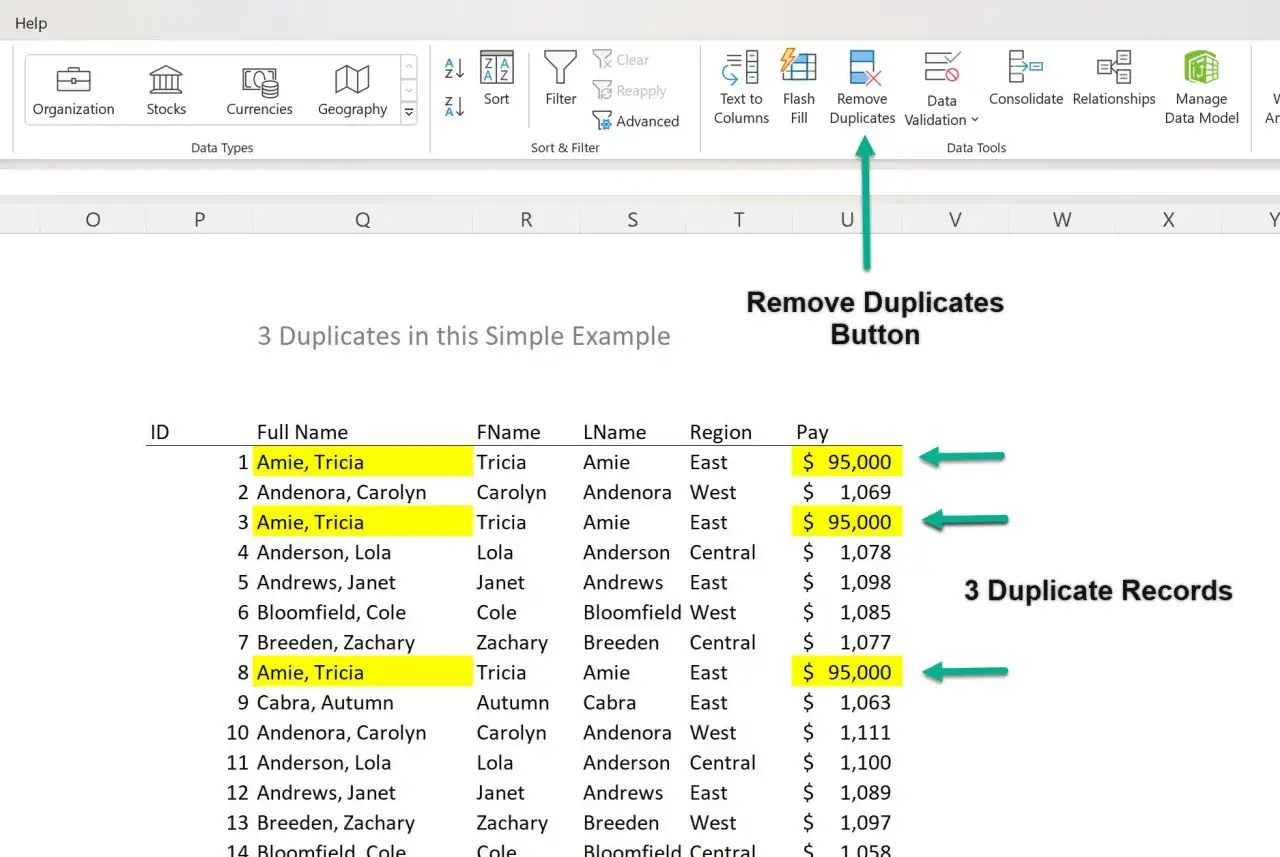
Najszybszy sposób na usunięcie powtarzających się wierszy
Jeżeli masz gotową tabelę i chcesz po prostu pozbyć się kopii rekordów, najkrótsza droga prowadzi przez polecenie Usuń duplikaty. To rozwiązanie dobrze sprawdza się w listach klientów, eksportach z CRM, rejestrach sprzedaży czy arkuszach z danymi operacyjnymi, które trzeba oczyścić przed analizą.
Jak to zrobić krok po kroku
- Zaznacz dowolną komórkę w zakresie danych albo w tabeli.
- Wejdź w kartę Dane i wybierz Usuń duplikaty.
- Jeśli arkusz ma nagłówki, upewnij się, że są uwzględnione w zakresie.
- W oknie dialogowym zaznacz kolumny, które mają decydować o tym, czy wiersz jest duplikatem.
- Potwierdź operację przyciskiem OK.
Ważny szczegół: Excel zachowuje pierwszy napotkany wiersz, a kolejne identyczne usuwa. To oznacza, że kolejność danych ma znaczenie. Jeśli najpierw posortujesz tabelę po dacie, cenie albo statusie, możesz świadomie zdecydować, która wersja rekordu zostanie w arkuszu.
Ja w takich sytuacjach zawsze zaczynam od kopii arkusza. Cofnięcie zmian jest zwykle możliwe od razu skrótem Ctrl+Z, ale przy danych biznesowych nie polegam wyłącznie na cofnięciu jednej akcji. Lepiej zabezpieczyć się wcześniej. Jeśli jednak nie każdy powtarzający się wpis jest błędem, trzeba doprecyzować, co dokładnie Excel ma uznać za duplikat.Kiedy jedno kliknięcie wystarczy, a kiedy może zniekształcić dane
Polecenie usuwania duplikatów działa świetnie wtedy, gdy wiersze są naprawdę kopią jeden do jednego albo gdy masz jasną definicję unikalności. Problem zaczyna się wtedy, gdy dwie pozycje wyglądają podobnie, ale biznesowo znaczą coś innego. W analizie danych to częsty błąd: ktoś usuwa „powtórki”, a w praktyce kasuje poprawne rekordy.
Typowe sytuacje, w których trzeba uważać
- Powtarzające się nazwiska nie muszą oznaczać duplikatów, jeśli analizujesz osoby z różnych oddziałów lub o różnych identyfikatorach.
- Te same zamówienia z inną datą aktualizacji mogą wyglądać jak kopie, ale są kolejnymi wersjami tego samego procesu.
- Różne formaty tej samej wartości potrafią zmylić użytkownika: Excel porównuje to, co widzi w komórce, więc identyczna data zapisana innym formatem może zostać potraktowana jako unikalna.
- Dane z sumami częściowymi lub konspektem trzeba najpierw uprościć, bo w takiej strukturze usuwanie duplikatów nie działa poprawnie.
W praktyce najlepiej myśleć nie o „duplikacie” w sensie wizualnym, tylko o regule porównania. Dla jednego arkusza kluczowy będzie e-mail, dla innego numer faktury, a dla jeszcze innego kombinacja klient + data + produkt. To właśnie ta reguła decyduje, czy po czyszczeniu zostanie zdrowy zestaw danych, czy przypadkowa mieszanka rekordów. Skoro reguła porównania jest tak ważna, warto zobaczyć, jak ustawić ją poprawnie dla części kolumn.
Jak ustawić zakres porównania, gdy duplikaty dotyczą tylko części kolumn
To najczęstszy scenariusz w pracy z arkuszami biznesowymi. Rzadko kiedy chcesz usuwać rekordy na podstawie całego wiersza. Zazwyczaj liczy się tylko kilka pól, na przykład identyfikator klienta, adres e-mail albo numer dokumentu. Wtedy właśnie wybór kolumn ma największe znaczenie.
| Sytuacja | Jakie kolumny porównywać | Co dostaniesz po czyszczeniu |
|---|---|---|
| Lista kontaktów | E-mail lub numer telefonu | Jedną wersję każdego kontaktu |
| Rejestr faktur | Numer faktury | Jeden rekord na dokument |
| Arkusz zamówień | ID zamówienia lub połączenie klient + data + produkt | Tylko unikalne transakcje |
| Katalog produktów | Indeks SKU lub kod produktu | Jedną pozycję na produkt |
Najważniejsza zasada brzmi: jeśli nie zaznaczysz jakiejś kolumny, Excel nie użyje jej do sprawdzania duplikatów, ale i tak usunie cały wiersz, jeśli pozostałe zaznaczone kolumny się powtórzą. To bywa zaskakujące, bo ludzie zakładają, że niezaznaczona kolumna zostanie „nietykalna”. Nie zostanie, jeśli sam wiersz wypadnie z arkusza.
Dlatego przy danych analitycznych często robię dwie rzeczy: najpierw ustalam, jaki zestaw pól naprawdę identyfikuje rekord, a dopiero potem uruchamiam deduplikację. Jeśli nie chcesz usuwać danych od razu, masz jeszcze kilka bezpieczniejszych metod. Właśnie one przydają się szczególnie wtedy, gdy wynik ma być tylko kopią roboczą albo elementem automatycznego procesu.
Co wybrać zamiast ręcznego kasowania rekordów
Nie każda sytuacja wymaga trwałego usuwania danych z arkusza. Czasem chcesz tylko wyciągnąć unikalne wartości, czasem zaznaczyć powtórki kolorem, a czasem przygotować proces, który będzie działał sam po każdym imporcie. W takich przypadkach ręczne czyszczenie jest po prostu zbyt kruche.
| Metoda | Do czego służy | Plus | Ograniczenie |
|---|---|---|---|
| Usuń duplikaty | Trwałe usunięcie powtarzających się wierszy | Najszybsze rozwiązanie | Kasuje dane bezpośrednio z zakresu |
| Filtr zaawansowany | Wyciągnięcie unikalnych rekordów do innej lokalizacji | Nie rusza oryginału | Wymaga dodatkowego kroku kopiowania |
UNIQUE |
Dynamiczna lista unikalnych wartości lub wierszy | Odświeża się automatycznie | Działa najlepiej w nowszych wersjach Excela |
| Power Query | Powtarzalne czyszczenie importów i raportów | Dobrze nadaje się do automatyzacji | Wymaga jednorazowego przygotowania zapytania |
Kiedy użyć formuły UNIQUE
Formuła UNIQUE przydaje się wtedy, gdy chcesz otrzymać nową listę bez nadpisywania źródła. Przykład jest prosty: jeśli w kolumnie A masz listę klientów z powtórkami, wpis =UNIQUE(A2:A100) zwróci tylko unikalne wartości. Jeśli pracujesz na wielu kolumnach, możesz podać cały zakres i Excel zwróci unikalne wiersze. To wygodne przy analizie, bo wynik żyje obok danych źródłowych i nie wymaga ręcznego kasowania.
Przeczytaj również: Analiza danych w Excelu - Od raportu do decyzji. Jak zacząć?
Kiedy lepiej postawić na Power Query
Jeśli co miesiąc dostajesz ten sam eksport z systemu sprzedażowego albo z CRM, Power Query zwykle wygrywa z ręcznym klikalnym czyszczeniem. Raz ustawiasz transformację, a potem odświeżasz dane i gotowe. Dla mnie to najbardziej sensowny wybór tam, gdzie arkusz jest tylko etapem w szerszym procesie analitycznym, a nie jednorazową tabelą do szybkiej korekty. Zanim jednak przejdziesz do automatyzacji, dobrze znać błędy, które najłatwiej popełnić przy zwykłym czyszczeniu.
Najczęstsze błędy przy czyszczeniu duplikatów
Najwięcej problemów nie bierze się z samego narzędzia, tylko z tego, że użytkownik zakłada zbyt dużo. Excel robi dokładnie to, co mu każesz, ale nie interpretuje intencji biznesowej. I właśnie tu pojawiają się kosztowne pomyłki.
- Brak kopii zapasowej przed czyszczeniem danych.
- Zbyt szerokie zaufanie do nazwy lub imienia zamiast do stabilnego identyfikatora.
- Usuwanie rekordów po sortowaniu bez świadomego wyboru, która wersja ma zostać.
- Pomijanie kolumn pomocniczych, które niosą ważny kontekst, na przykład status, źródło lub data aktualizacji.
- Mylenie filtrowania z usuwaniem - filtr tylko ukrywa duplikaty, a nie kasuje ich z arkusza.
W praktyce największą różnicę robi nie samo kliknięcie, ale krótki audyt przed działaniem: co jest identyfikatorem, co jest opisem, a co tylko atrybutem pomocniczym. Jeżeli te trzy rzeczy są rozdzielone, ryzyko błędu spada dramatycznie. A jeśli duplikaty wracają regularnie, najlepiej od razu zbudować prosty proces zamiast powtarzać ręczne sprzątanie.
Jak zbudować prosty proces, żeby duplikaty nie wracały
Jeśli dane pojawiają się tylko raz, szybkie czyszczenie wystarczy. Jeśli jednak pracujesz z importami z ERP, CRM, platformy e-commerce albo z arkuszy od kilku osób, ręczne usuwanie duplikatów zaczyna być stratą czasu. Wtedy lepiej ustawić mały, powtarzalny proces.
- Trzymaj surowy import w osobnej zakładce i nie poprawiaj go bezpośrednio.
- Buduj warstwę czyszczącą obok danych źródłowych, zamiast nadpisywać oryginał.
- Przy danych cyklicznych stosuj Power Query, bo zapisuje kroki i odtwarza je przy każdym odświeżeniu.
- Jeśli raport ma być lekki i czytelny, generuj go z unikalnej listy zamiast ręcznie usuwać rekordy.
- Ustal jedną regułę identyfikacji duplikatu dla całego zespołu, żeby każdy czytał arkusz tak samo.
To podejście jest bardziej biznesowe niż „kliknij i usuń”, ale właśnie ono najlepiej skaluje się w analizie danych. W pojedynczym pliku wystarczy narzędzie z karty Dane, natomiast w regularnym obiegu danych lepiej myśleć o procesie niż o jednorazowej akcji. Jeśli chcesz pracować szybciej i bezpieczniej, trzymaj się prostego układu: kopia źródła, jasna reguła duplikatu, a dopiero potem czyszczenie. Dzięki temu porządkowanie arkusza przestaje być ręczną walką z chaosem, a staje się normalnym etapem pracy z danymi.