
Dobrze przeprowadzona analiza ankiety nie zaczyna się od wykresu, tylko od porządku w danych i jasnej decyzji, co właściwie ma zostać udowodnione. W tym tekście pokazuję, jak przejść od surowych odpowiedzi do sensownych wniosków: od przygotowania arkusza, przez liczenie wyników w Excelu, po interpretację procentów, błędy i moment, w którym warto już zautomatyzować proces. Jeśli badanie ma wspierać decyzję biznesową, a nie tylko „ładnie wyglądać”, właśnie te elementy robią największą różnicę.
Najpierw uporządkuj odpowiedzi, potem licz i interpretuj je w kontekście celu badania
- Jedna odpowiedź w wierszu, jedno pytanie w kolumnie to układ, który najszybciej daje się analizować w Excelu.
- Przy małej próbie jeden głos potrafi zmienić wynik o kilka punktów procentowych, więc zawsze pokazuj też liczebność n.
- Do zliczania odpowiedzi najczęściej wystarczą
COUNTIF,COUNTIFS, tabela przestawna i filtr. - W pytaniach otwartych najpierw tworzę kategorie odpowiedzi, dopiero potem je zliczam.
- Średnia nie zawsze jest najlepszym opisem skali 1-5; często lepiej pokazują ją mediana i rozkład odpowiedzi.
- Jeśli ankieta wraca cyklicznie lub ma setki rekordów, Excel warto wesprzeć automatyzacją lub Power Query.
Zacznij od danych, które da się naprawdę policzyć
Najwięcej błędów powstaje nie podczas interpretacji, tylko wcześniej, przy porządkowaniu arkusza. Ja zawsze sprawdzam trzy rzeczy: czy każdy respondent ma jeden wiersz, czy każda zmienna jest w osobnej kolumnie i czy odpowiedzi otwarte zostały zapisane w sposób możliwy do zakodowania. To brzmi banalnie, ale bez tego nawet najlepsza tabela przestawna pokaże tylko chaos.
W praktyce dobrze przygotowany plik z badania kwestionariuszowego ma prostą logikę: identyfikator odpowiedzi, data wypełnienia, pytania zamknięte, metryczka i osobna kolumna na uwagi lub komentarze. Przy pytaniach wielokrotnego wyboru nie zostawiam kilku odpowiedzi w jednej komórce, jeśli planuję później analizę segmentów. Rozbijam je albo koduję tak, by każdą opcję dało się zliczyć osobno. Dzięki temu nie trzeba ręcznie poprawiać wyniku za każdym razem, gdy ktoś zada nowe pytanie o tę samą ankietę.
Warto też od razu zaznaczyć brakujące dane. Puste komórki, odpowiedzi „nie wiem” i odpowiedzi spoza skali nie są tym samym, więc nie powinny trafiać do jednego worka. Jeśli tego nie rozdzielisz, łatwo zawyżyć albo zaniżyć wynik, zwłaszcza przy małej próbie. A kiedy dane są już czyste, można przejść do liczenia bez obaw, że Excel policzy coś innego niż trzeba.
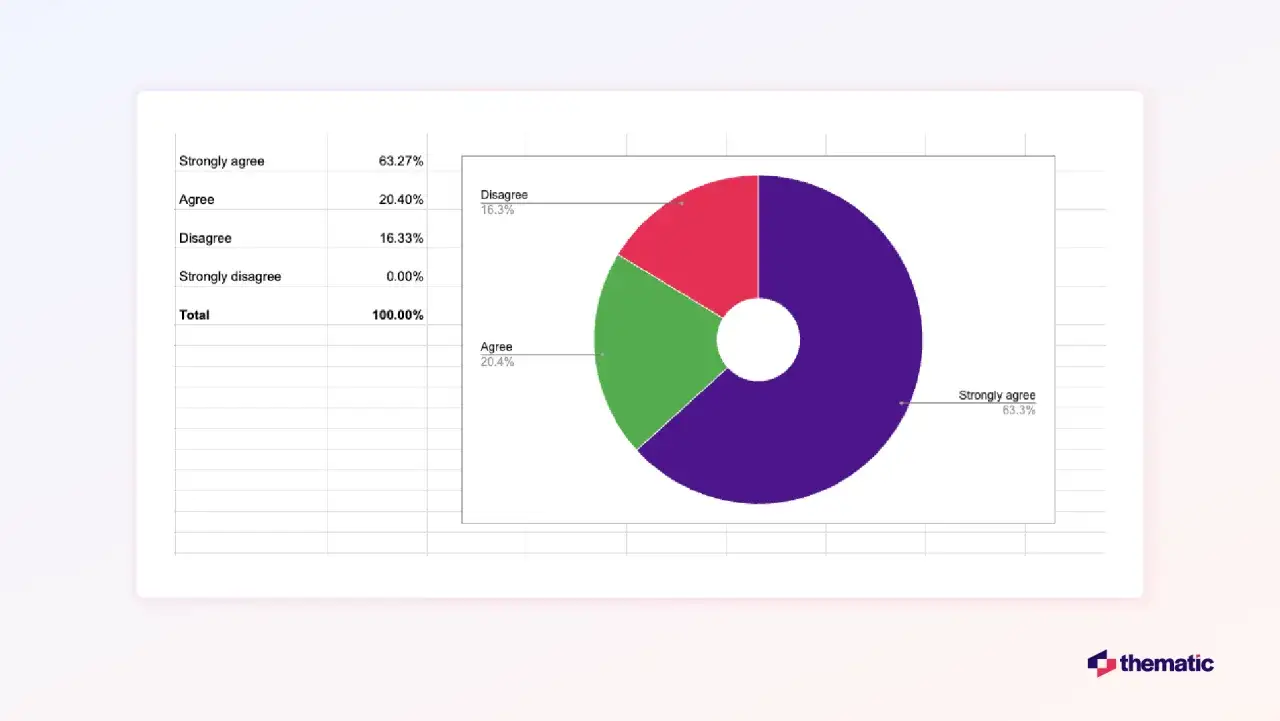
Policz odpowiedzi w Excelu szybciej niż ręcznie
Do podstawowego podsumowania nie potrzeba ciężkiego narzędzia. W Excelu najczęściej wykorzystuję kilka funkcji i jedną rzecz, która oszczędza najwięcej czasu: tabelę przestawną. Microsoft opisuje ją jako sposób na szybkie podsumowanie i analizę danych, i dokładnie tak jej używam przy ankietach.
| Typ pytania | Co policzyć | Najwygodniejsze narzędzie w Excelu | Praktyczna uwaga |
|---|---|---|---|
| Jednokrotnego wyboru | Liczbę odpowiedzi i udział procentowy |
COUNTIF, tabela przestawna |
Dobre do pytań typu „tak/nie” albo wyboru jednej opcji |
| Wielokrotnego wyboru | Liczbę wskazań każdej opcji |
COUNTIFS, osobne kolumny, tabela przestawna |
Najpierw trzeba rozbić odpowiedzi na pojedyncze zmienne |
| Skala ocen 1-5 | Średnią, medianę i rozkład odpowiedzi |
AVERAGE, MEDIAN, PivotTable |
Sama średnia bywa myląca, jeśli odpowiedzi są spolaryzowane |
| Pytania z metryczki | Porównanie grup, np. wiek, dział, lokalizacja | Tabela przestawna, filtr, FILTER w nowszym Excelu |
Tu najłatwiej znaleźć różnice między segmentami |
| Pytania otwarte | Powtarzające się motywy i kategorie odpowiedzi | Ręczne kodowanie, filtr tekstowy, tabela pomocnicza | Najpierw porządkuję treść, potem ją zliczam |
Jeśli pracujesz na większym zestawie danych, zamień zakres na tabelę Excela. To ułatwia filtrowanie, odświeżanie i rozbudowę arkusza, kiedy dopisują się kolejne odpowiedzi. W nowszym Excelu przydaje się też FILTER, bo pozwala szybko wyciągać tylko wybraną grupę rekordów bez ręcznego przepinania filtrów. Do prezentacji wyników używam przede wszystkim wykresów słupkowych dla pojedynczych odpowiedzi, skumulowanych słupków dla struktury odpowiedzi i wykresów liniowych wtedy, gdy porównuję kilka fal badania w czasie. Gdy policzysz podstawy, najciekawsze pytanie brzmi już nie „ile”, tylko „dlaczego właśnie tak wyszło”.
Interpretuj wynik w kontekście wielkości próby i celu badania
Same procenty potrafią być zdradliwe. Przy 20 odpowiedziach jedna osoba to 5%, więc wynik zmienia się gwałtownie po każdym kolejnym głosie. Przy 200 odpowiedziach ten sam głos waży już 0,5%, dlatego te same różnice wyglądają zupełnie inaczej. Z tego powodu zawsze patrzę na dwa poziomy naraz: na procent i na liczbę odpowiedzi, czyli liczebność próby, oznaczaną często jako n.
Jeśli badanie dotyczy satysfakcji, nie wystarczy powiedzieć, że 68% osób oceniło proces pozytywnie. Chcę jeszcze wiedzieć, kto tak odpowiedział. Inaczej traktuję wynik z całej organizacji, a inaczej z jednego działu, jednej lokalizacji albo jednej grupy wiekowej. Właśnie tu metryczka staje się użyteczna, bo pozwala zobaczyć, czy problem jest ogólny, czy dotyczy tylko konkretnego segmentu.
Przy pytaniach z pięciostopniową skalą ocen, czyli porządkową skalą od bardzo nisko do bardzo wysoko, średnia bywa pomocna, ale nie powinna być jedyną liczbą. Jeśli odpowiedzi są rozrzucone po skrajach, mediana i sam rozkład mówią więcej niż elegancka średnia z dwoma miejscami po przecinku. Ja zwykle patrzę na trzy rzeczy naraz: dominującą odpowiedź, medianę oraz odsetek ocen negatywnych i pozytywnych. Dzięki temu wynik nie wygląda lepiej, niż jest w rzeczywistości.
W pytaniach otwartych kluczowe jest kodowanie, czyli przypisywanie podobnych wypowiedzi do tych samych kategorii. Z 40 komentarzy może wyjść 5 głównych motywów, a z 300 komentarzy już 10-12 sensownych grup. To nadal jest analiza jakościowa, ale uporządkowana tak, by dało się ją pokazać zarządowi bez przepisywania wszystkiego ręcznie. I właśnie taki most między treścią a liczbą jest zwykle najbardziej wartościowy.
Najczęstsze błędy, które psują opracowanie wyników
W praktyce widzę kilka powtarzalnych potknięć. Pierwsze to liczenie procentów bez wskazania podstawy, czyli bez informacji, ile osób faktycznie odpowiedziało. Drugie to mieszanie pytań jednokrotnego i wielokrotnego wyboru, jakby były identyczne. Trzecie to wyciąganie wniosków z jednego wykresu bez sprawdzenia, czy dane w ogóle są porównywalne.
- Zbyt mała próba - przy kilkunastu odpowiedziach każdy procent robi się zbyt ciężki interpretacyjnie.
- Brak czyszczenia danych - duplikaty, puste pola i literówki potrafią zniekształcić wynik bardziej, niż się wydaje.
- Średnia zamiast rozkładu - szczególnie przy ocenach 1-5 i odpowiedziach spolaryzowanych.
- Jedna tabela dla wszystkiego - bez segmentacji nie widać różnic między grupami respondentów.
- Przesyt wykresów - kiedy każdy slajd ma inny wykres, odbiorca przestaje widzieć sens całości.
- Interpretacja bez pytania badawczego - wtedy arkusz jest policzony, ale raport niczego nie rozstrzyga.
Najdroższy błąd jest zwykle ten sam: zbyt szybkie przejście od surowych odpowiedzi do wniosku. Najpierw sprawdzam, czy wynik jest stabilny, dopiero potem zastanawiam się, co znaczy. To oszczędza korekt, zwłaszcza wtedy, gdy raport ma trafić do zespołu decyzyjnego, a nie tylko do archiwum. Gdy te ryzyka są pod kontrolą, można sensownie ocenić, czy Excel nadal wystarcza, czy warto wejść poziom wyżej.
Kiedy Excel wystarczy, a kiedy lepiej zautomatyzować proces
Dla małej lub średniej ankiety Excel jest zwykle wystarczający, o ile badanie nie zmienia się co tydzień. Jeśli mam kilkadziesiąt albo kilkaset odpowiedzi i jednorazowy raport, dobrze zbudowany arkusz, tabela przestawna i kilka formuł załatwiają sprawę. Problem zaczyna się wtedy, gdy ankieta wraca cyklicznie, danych przybywa albo trzeba porównywać wiele fal badania.
| Sytuacja | Excel | Lepsze wsparcie automatyzacji |
|---|---|---|
| Jednorazowy raport z kilkudziesięciu odpowiedzi | Wystarczy | Nie jest konieczne |
| Badanie kwartalne, ten sam układ pytań | Wystarczy, jeśli arkusz ma stały szablon | Power Query lub gotowy proces importu |
| Setki lub tysiące odpowiedzi miesięcznie | Da się, ale rośnie ryzyko błędów ręcznych | Automatyzacja importu i odświeżania danych |
| Wiele źródeł danych, np. Forms, CRM i proste pliki CSV | Staje się niewygodny | Power Query, Power BI albo integracja ETL |
| Potrzeba stałego monitoringu wskaźników | Możliwy, ale pracochłonny | Pulpit raportowy z automatycznym odświeżaniem |
Power Query to narzędzie do pobierania, czyszczenia i łączenia danych, Power BI traktuję jako warstwę raportową do wizualizacji i pulpitów, a ETL oznacza po prostu pobranie, przekształcenie i załadowanie danych do jednego modelu. Ja patrzę na to pragmatycznie: jeśli kilka osób ma co miesiąc ręcznie poprawiać ten sam plik, to znaczy, że proces już wymaga automatyzacji. Wtedy nie chodzi o „większy prestiż narzędzia”, tylko o ograniczenie błędów i czasu pracy. Taki układ dobrze pasuje do organizacji, które chcą szybciej przechodzić od zbierania odpowiedzi do działania.
Co warto zostawić po zakończeniu pracy z ankietą
Dobra analiza ankiety nie kończy się na wykresie, tylko na krótkiej, czytelnej odpowiedzi: co się wydarzyło, dlaczego to ważne i co z tego wynika dla organizacji. Jeśli mam przygotować raport, zwykle zostawiam trzy warstwy informacji: wynik ogólny, różnice między grupami i jeden konkretny wniosek operacyjny. To wystarcza, żeby odbiorca nie zgubił się w szczegółach.
- Wynik ogólny - jedna liczba lub jeden wykres, który pokazuje skalę zjawiska.
- Segment różniący się od reszty - dział, lokalizacja, wiek, staż lub inna metryczka.
- Najmocniejszy sygnał jakościowy - powtarzający się komentarz lub motyw z odpowiedzi otwartych.
- Jedna rekomendacja - konkretne działanie, a nie opis problemu bez decyzji.
Jeśli mam zostawić jedną zasadę, to tę: najpierw porządkuję dane, potem liczę, a dopiero na końcu interpretuję. Tak właśnie powstaje raport, który nie tylko wygląda profesjonalnie, ale naprawdę pomaga podjąć decyzję. A to jest różnica między samym zbiorem odpowiedzi a badaniem, z którego da się wyciągnąć wartość.