
W serwisie firmowym kontrola indeksu bywa ważniejsza niż sama publikacja treści. Dobrze ustawione dyrektywy pozwalają ukryć strony techniczne, ograniczyć duplikaty i zdecydować, które linki mają być śledzone przez roboty. W praktyce chodzi o dwa różne mechanizmy, często wrzucane do jednego worka pod skrótem noindex nofollow, choć każdy z nich rozwiązuje inny problem.
To są najważniejsze zasady kontrolowania indeksu i linków
- Noindex usuwa stronę z indeksu, ale robot musi ją najpierw zobaczyć.
- Nofollow dotyczy linków i sygnalizuje, że nie chcesz, by robot podążał za odnośnikami z danej strony lub konkretnego linku.
- W przypadku plików PDF i innych zasobów nienależących do HTML często lepszy jest nagłówek HTTP niż tag w kodzie.
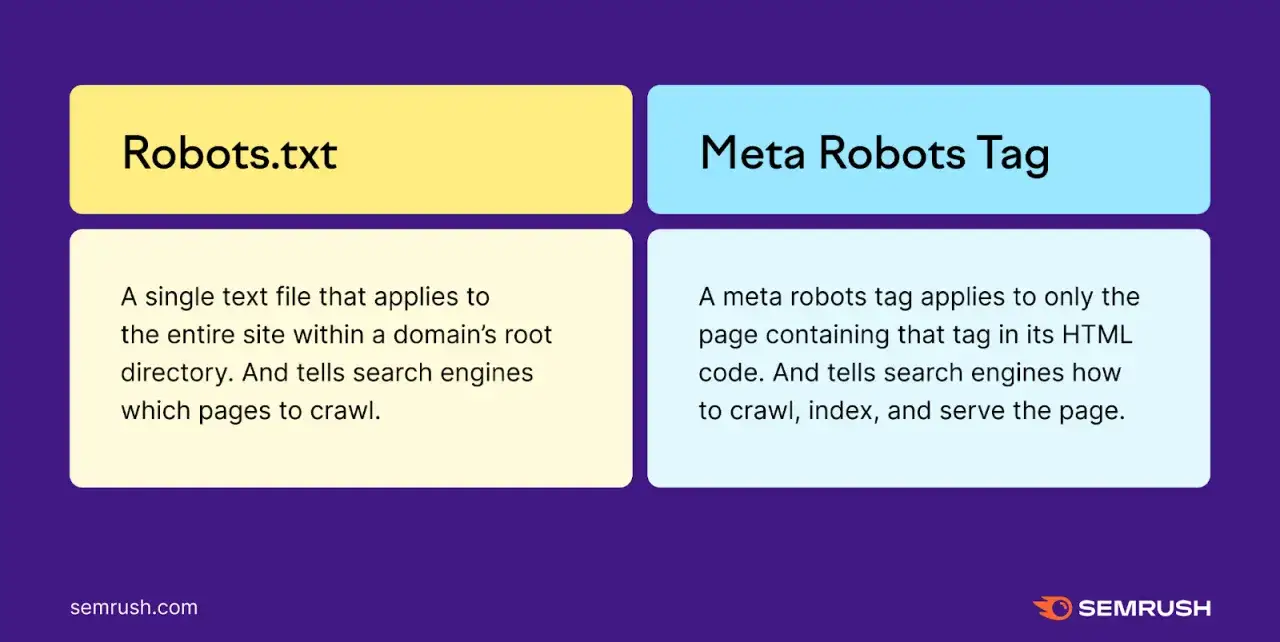
- Robots.txt nie jest narzędziem do wycinania strony z wyników, tylko do ograniczania dostępu crawlera.
- W serwisie firmowym te mechanizmy najczęściej rozwiązują problem duplikatów, stron technicznych, paneli i linków sponsorowanych.
Jak odróżnić indeksowanie od podążania za linkami
W praktyce rozdzielam trzy decyzje. Czy strona ma być pobrana przez robota, czy ma trafić do indeksu, i czy robot ma iść dalej za linkami. To nie jest to samo: strona może zostać odwiedzona, a mimo to nie pojawić się w wynikach; może też pozostać widoczna, ale nie przekazywać sygnału przez linki. To rozróżnienie oszczędza sporo błędów, zwłaszcza w serwisach z dużą liczbą podstron, filtrów i automatycznie generowanych URL-i. Kiedy już to widać, łatwiej dobrać właściwy znacznik i nie pomylić go z blokadą w robots.txt. Następny krok to miejsce wdrożenia, bo właśnie tam najczęściej robi się bałagan.
Jak działa noindex i gdzie go umieścić
Na stronie HTML najczęściej używa się tagu w sekcji , a dla plików PDF, obrazów i innych zasobów lepiej sprawdza się nagłówek HTTP. Meta tag działa szeroko, jeśli wpiszesz robots, albo tylko dla Google, jeśli użyjesz googlebot. W praktyce najważniejsze jest jedno: robot musi stronę zobaczyć, żeby zareagować na polecenie. Jeśli plik został wcześniej zablokowany przez robots.txt, dyrektywa nie zadziała tak, jak oczekujesz.
| Mechanizm | Gdzie działa | Kiedy wybrać | Ograniczenie |
|---|---|---|---|
|
HTML | Standardowe strony | Wymaga dostępu robota do treści |
X-Robots-Tag: noindex |
HTTP header | PDF, pliki, zasoby bez HTML | Trzeba ustawić na poziomie serwera lub CDN |
robots.txt |
Crawl | Ograniczenie pobierania | Nie usuwa samo z indeksu |
Jak podaje Google Search Central, blokada crawl i blokada indeksowania to dwa różne poziomy kontroli. Ja zawsze zaczynam od upewnienia się, że robot ma dostęp do treści, a dopiero potem wycinam ją z indeksu. Dzięki temu zmiana ma szansę zostać odczytana przy pierwszym kolejnym wejściu, zamiast wisieć w systemie przez długi czas. Jeśli chcesz ograniczyć też podążanie za linkami z całej strony, można dodać wariant noindex, nofollow, ale używam go tylko wtedy, gdy naprawdę potrzebuję obu efektów naraz. To prowadzi do drugiego pytania: kiedy w ogóle warto sięgać po nofollow.
Jak działa nofollow i kiedy ma sens
Nofollow dotyczy linków, nie całej strony. W praktyce oznacza to relację przy konkretnym odnośniku, na przykład w treści sponsorowanej, w komentarzu albo w sekcji z materiałami dodawanymi przez użytkowników. Google Search Central traktuje dziś nofollow jako wskazówkę, a nie twardy zakaz, dlatego nie ustawiam go mechanicznie przy każdym linku wychodzącym. Jeśli link jest redakcyjny, wartościowy i normalnie wpisuje się w treść, zostawiam go bez atrybutu. Jeśli link ma charakter komercyjny, lepiej użyć rel="sponsored"; jeśli jest tworzony przez użytkowników, rozsądniejszy bywa rel="ugc". Nofollow zostawiam na sytuacje pośrednie, kiedy nie chcę wzmacniać ani problematycznego źródła, ani konkretnego sygnału rankingowego.
| Sytuacja | Co oznaczyć | Dlaczego |
|---|---|---|
| Link sponsorowany |
sponsored lub nofollow
|
Oddziela treść komercyjną od redakcyjnej |
| Komentarze i forum |
ugc lub nofollow
|
Ogranicza ryzyko link spamu |
| Niepewne źródło | nofollow |
Nie chcesz wiązać z nim swojej domeny |
| Normalny link redakcyjny | Brak atrybutu | Naturalny profil linków i pełny kontekst treści |
Największy błąd, jaki widzę, to traktowanie nofollow jak obowiązkowego dodatku do każdego linku wychodzącego. To spłaszcza profil odnośników i odbiera treściom naturalność. W serwisie biznesowym lepiej działa selektywność: oznaczasz tylko to, co rzeczywiście wymaga dystansu, a resztę zostawiasz czytelnikom i wyszukiwarkom w standardowym trybie. Kiedy to uporządkujesz, czas przejść do konkretnych scenariuszy, które pojawiają się najczęściej w praktyce SEO.
Gdzie te dyrektywy naprawdę pomagają w serwisie firmowym
W projektach związanych z marketingiem cyfrowym i automatyzacją najczęściej nie walczę z jedną stroną, tylko z całym zbiorem podobnych adresów. Właśnie wtedy właściwe ustawienie indeksowania robi największą różnicę. Poniżej zestawiam sytuacje, w których decyzja jest najprostsza.
| Sytuacja | Najczęstsza decyzja | Dlaczego to działa |
|---|---|---|
| Strona podziękowania po formularzu | noindex |
Ma sens po konwersji, ale rzadko wnosi wartość w wyszukiwarce |
| Wyniki wewnętrznej wyszukiwarki | noindex |
Tworzą dużo słabych i powtarzalnych URL-i |
| Staging, testy, wersje robocze | Ograniczenie dostępu, opcjonalnie noindex
|
Wersja robocza nie powinna konkurować z produkcją |
| Filtrowane listy produktów lub artykułów |
canonical, czasem noindex
|
Porządkuje duplikaty i ogranicza bałagan w indeksie |
| PDF-y sprzedażowe i materiały do pobrania | X-Robots-Tag: noindex |
Plik nie musi rywalizować o ruch organiczny |
| Linki sponsorowane i partnerskie |
sponsored lub nofollow
|
Rozdziela relację komercyjną od linkowania redakcyjnego |
Właśnie tu najlepiej widać, że nie każdy problem da się rozwiązać jednym znacznikiem. Czasem noindex wystarczy, czasem canonical daje lepszy efekt, a czasem najrozsądniejsze jest po prostu zabezpieczenie dostępu hasłem. Z tego powodu następna sekcja dotyczy błędów, które najczęściej psują cały plan. Na portalu o transformacji cyfrowej i automatyzacji takie pomyłki pojawiają się częściej, niż wielu osobom się wydaje.
Najczęstsze błędy, które kosztują widoczność
- Blokowanie URL-i w robots.txt przed wdrożeniem noindex - robot nie zobaczy dyrektywy, więc strona może nadal krążyć w wynikach z innych sygnałów.
- Ustawianie noindex na stronie, która ma być kanoniczna - wtedy sam sobie odbierasz ruch na wersji, którą chcesz promować.
- Różne dyrektywy na mobile i desktop - przy indeksowaniu mobile-first taka niespójność potrafi rozwalić całą interpretację.
- Zmiana tagu dopiero po renderze JavaScript - jeśli robot nie doczeka do końca, zobaczy stan początkowy, nie końcowy.
- Nofollow na wszystkich linkach wychodzących - to nadmierny odruch, który osłabia naturalność linkowania.
- Mylenie noindex z prywatnością - jeśli coś ma być naprawdę ukryte, lepsza jest autoryzacja niż sam znacznik robots.
Najwięcej problemów wynika nie z samej decyzji, tylko z kolejności działań. Jeśli robot ma zobaczyć zmianę, strona musi zostać ponownie odwiedzona, a to bywa szybkie na mocnych URL-ach i wolniejsze na adresach o niskim priorytecie. Gdy wiem, co zostało ustawione, przechodzę do sprawdzenia, czy bot widzi dokładnie to samo, co ja.
Jak sprawdzić, czy wdrożenie działa
- Sprawdzam źródło HTML albo nagłówek HTTP, nie tylko widok w przeglądarce.
- W Search Console używam URL Inspection, żeby zobaczyć wersję odczytaną przez robota.
- Patrzę w raport Page indexing, czy system odczytał dyrektywę
noindex. - W razie potrzeby proszę o ponowne zindeksowanie, zamiast czekać biernie na kolejny crawl.
- Porównuję wersję desktop i mobile, jeśli serwis ma osobne szablony lub logikę renderowania.
Jeśli wynik się nie zmienia, zwykle winna jest blokada crawl albo błędna wersja szablonu. W praktyce taka diagnostyka oszczędza najwięcej czasu, bo zamiast zgadywać, od razu widzę, czy problem leży w kodzie, serwerze czy harmonogramie odwiedzin robota. To prowadzi do ostatniej, prostej zasady, którą stosuję przy każdej decyzji o indeksowaniu.
Jak podejmuję decyzję, co zostawić w indeksie, a co wyłączyć
- Zostawiam w indeksie strony, które mają własną wartość informacyjną, odpowiadają na intencję użytkownika i mogą zdobywać ruch organiczny.
- Wycinam noindexem strony techniczne, duplikaty, wyniki wyszukiwania i treści tymczasowe.
- Oznaczam linki wtedy, gdy problem dotyczy zaufania, płatnej współpracy albo treści dodawanych przez użytkowników.
- Nie mylę tych dyrektyw z prywatnością, bo do tego służą autoryzacja i kontrola dostępu.
W dobrze uporządkowanym serwisie te ustawienia nie zabierają widoczności. One porządkują indeks, dzięki czemu ważne treści mają większą szansę wybrzmieć, a szum techniczny przestaje konkurować z ofertą.